

Executive Summary
The GenAI investment narrative is shifting from training economics to deployment economics. While foundation model training remains strategically important, the emerging opportunity lies in “cheap intelligence”: infrastructure and techniques that make AI capability affordable, reliable, and scalable in production.
This thesis rests on three interdependent trends: post-training is becoming the primary locus of differentiation; inference optimization is where unit economics are won or lost; and agentic workloads are the forcing function separating viable platforms from demos. The next wave of defensible GenAI companies will look less like model labs and more like intelligence manufacturers.
The Economic Shift: Training to Inference
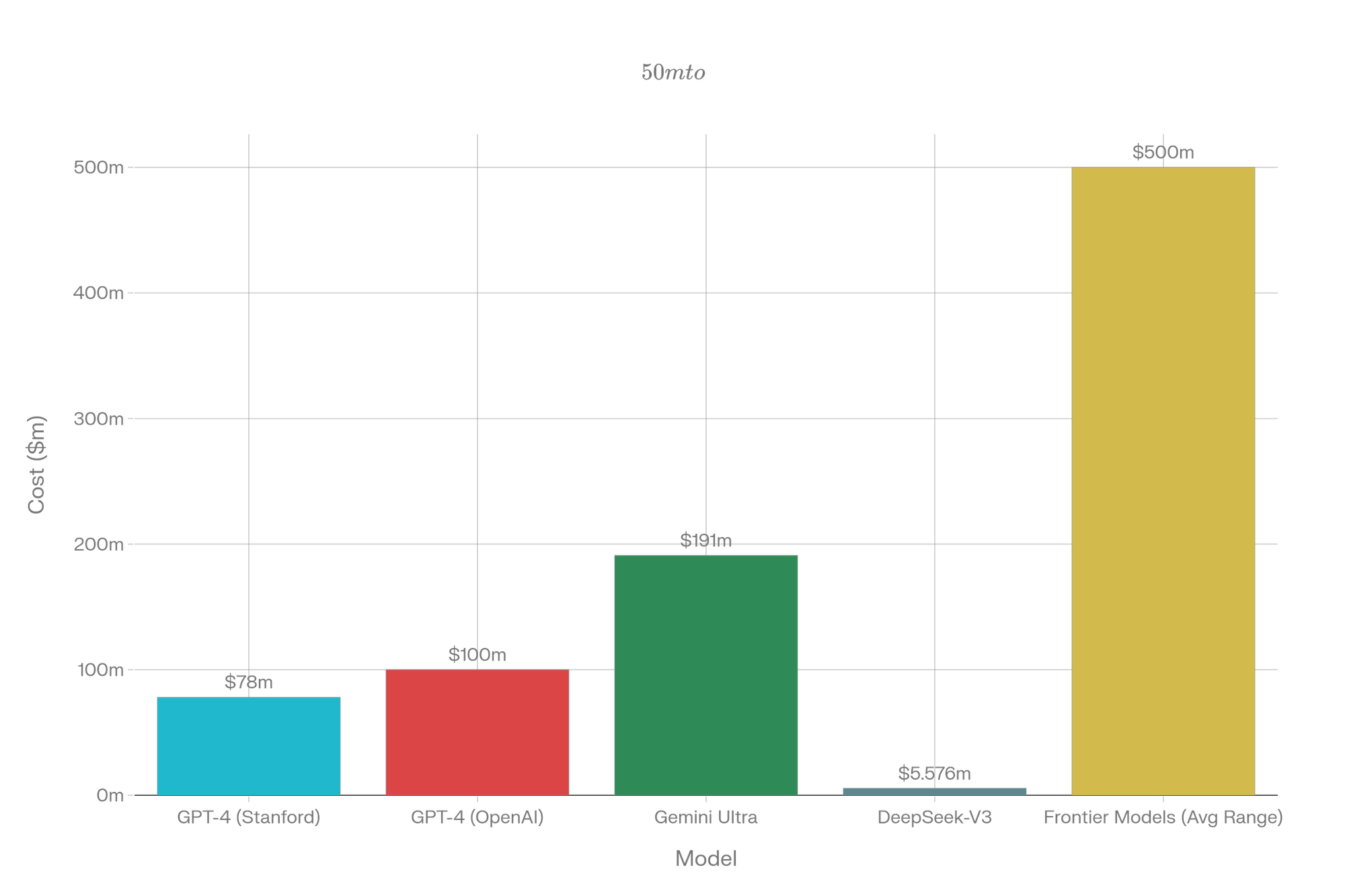
Foundation model training costs are well-characterized. Stanford's AI Index estimates ~$78M in compute for GPT-4 and ~$191M for Gemini Ultra. OpenAI CEO Sam Altman confirmed GPT-4 cost “more than” $100M end-to-end. However, by 2025 the story bifurcates: DeepSeek-V3 reports just $5.576M in training costs, while frontier models range from $50M-$1B.
For deployed systems, inference dominates the total cost of ownership. Epoch AI notes that aggregate inference cost over a model's lifetime often greatly exceeds one-time training cost. OpenAI's 2024 financials projected inference costs exceeding $2B annually, dwarfing amortized training costs. For models serving millions of users, inference typically costs 3-10x as much as training.
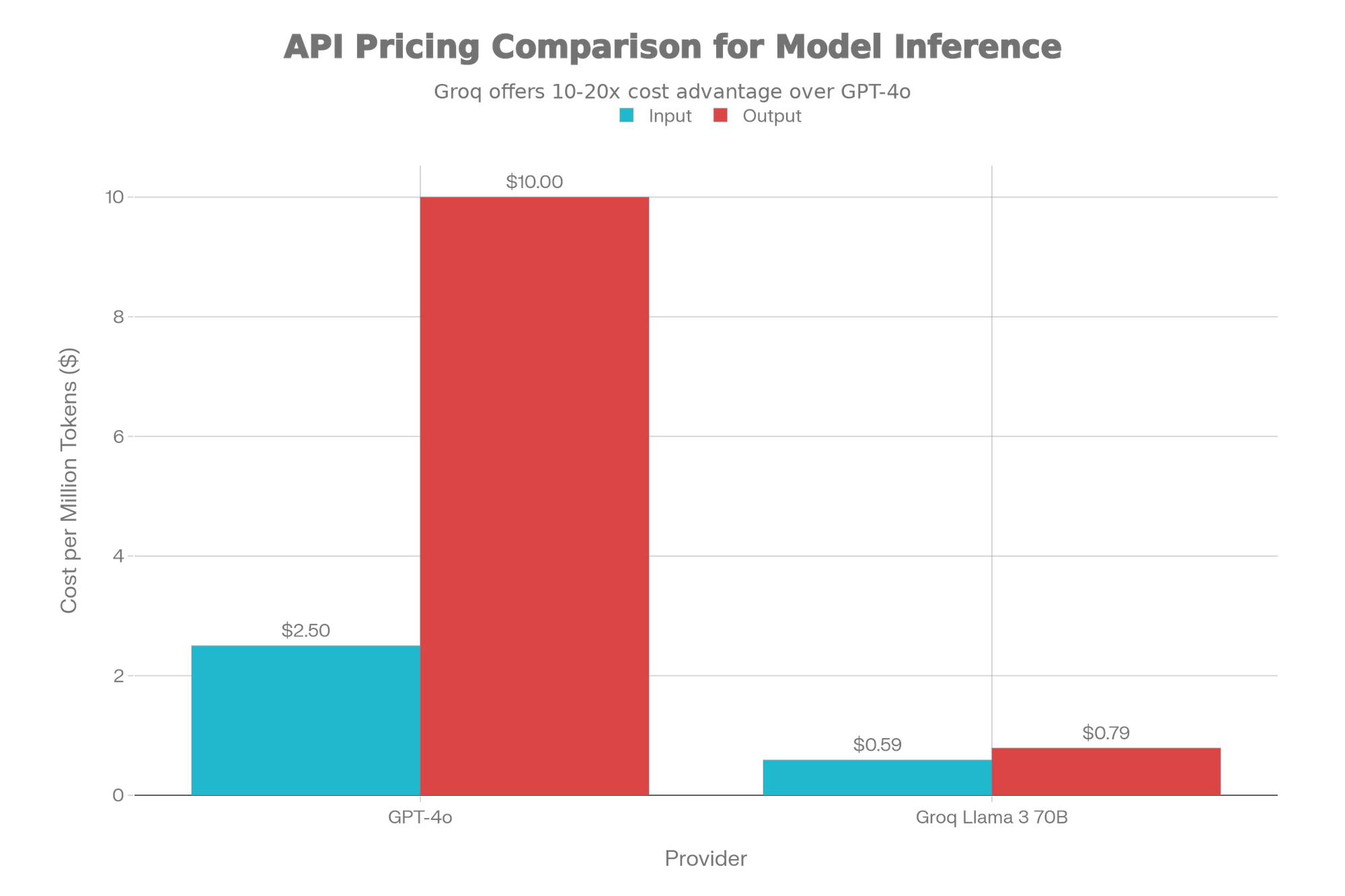
Current API pricing illustrates this reality: GPT-4o costs $2.50/$10 per million tokens (input/output), while specialized providers like Groq offer Llama 3 70B at $0.59/$0.79, a 10-20x cost advantage. For applications requiring multiple model calls (agents, complex RAG), costs compound to $0.05-$0.20 per task.
The critical insight: Training creates an asset; inference determines profitability. A 2x improvement in inference efficiency has a greater economic impact than a 2x reduction in training costs at scale.
Post-Training: Where Capability Becomes Product
Post-training (supervised fine-tuning, RLHF/RLAIF, distillation, domain specialization, and safety shaping) is where generic capability becomes a defensible product. Specialized models often outperform larger general models on specific tasks at a fraction of the cost.
Evidence: Bloomberg's BloombergGPT (50B parameters) outperforms GPT-3.5 on financial tasks despite being 3x smaller, with 60-70% inference cost advantages. Code-specialized models outperform larger general models while running at lower cost. A specialized 7B model costs $0.0001-0.0005 per query versus $0.01-0.03 for frontier models, a 20-100x difference decisive for high-volume applications.
Who's executing: OpenAI's fine-tuning API shows 300% year-over-year growth. Anthropic differentiates on Constitutional AI. Databricks (MosaicML) and Cohere's position on enterprise customization. Scale AI evolved from labeling to post-training services.
Moat durability: Defensible if you have proprietary domain data, unique preference models, or continuous evaluation pipelines. Not defensible if you're fine-tuning on public datasets or lack domain depth. Risk: If GPT-5/Claude 4 are sufficiently capable out-of-the-box, post-training value could compress. We assess this as moderate risk (30-40%) over 2-3 years, but economics and domain constraints suggest post-training remains valuable.
Inference Optimization: The Profit Center
Memory bandwidth, latency requirements, variable workloads, and marginal cost per token constrain inference. Multiple approaches compete:
Algorithmic: Quantization (2-4x speedup), speculative decoding (1.5-2.5x), context caching (50-90% cost reduction for RAG)
Hardware: Groq's custom LPU (10x speedup claims), Cerebras WSE-3, hyperscaler chips (AWS Inferentia, Google TPU v5e, Azure Maia)
Infrastructure: vLLM, TensorRT-LLM, model routing between small/large models
Current unit economics show that 10-50x cost advantages are achievable through optimization—the difference between profitability and unprofitability at scale.
Investment implications: Back infrastructure with durable advantages (hardware, serving frameworks with network effects) and workload-specific optimizations. Avoid generic API wrappers. Key questions: What's your cost per token? What's the technical source of advantage? Is it defensible over 12-24 months?
Agents: The Forcing Function
Agentic systems decompose tasks into sequences: planning, tool use, retrieval, execution, verification, and iteration. They make 5-50+ model calls per task, interact with external tools, and require memory and state management.
Economic impact: Agents amplify inference costs by an order of magnitude. A simple chatbot costs $0.01-0.03 per query; a code agent costs $0.10-0.60; a research agent $0.50-2.00. If intelligence costs $0.01/call, agents work on $1- $ 10 tasks. At $0.001/call (100x cheaper), they work for $0.10-1.00 tasks, a massive market expansion.
Current state: Agents show traction in narrow domains (code generation, customer support, data analysis) but fail frequently (20-40% rates) on complex tasks. Unlike 2016-2018, foundation models now handle tool use and self-correction, with sub-second latency enabling real-time flows. But technical and economic barriers remain.
Infrastructure gap: Production needs memory management, tool sandboxing, policy enforcement, observability, and cost controls. LangChain/LangSmith, E2B, and hyperscaler offerings are immature. This is an active investment opportunity.
Where Value Accrues: The Moat Analysis
We identify five defensibility categories:
1. Workflow Integration (High Durability): Embedding in systems of record (GitHub Copilot, Salesforce Einstein). Classic SaaS moat enhanced by GenAI.
2. Proprietary Data (Medium-High): Post-training on unique data (Bloomberg Terminal, healthcare systems). Durable if the data is unique and continuously updated. Risk: 2-3 years before foundation model improvements threaten.
3. Inference Efficiency (Medium): Hardware advantages last 2-4 years; algorithmic advantages 6-18 months. Risk: Commoditization as techniques diffuse.
4. Agent Infrastructure (Medium): Platforms for reliability and governance. Durable if network effects emerge. Risk: Hyperscalers could bundle (2-3 year window).
5. Evaluation (Low-Medium): Domain-specific evaluation. Defensible with unique expertise but not winner-take-all.
Key Risks
- Foundation models improve faster than expected (30-40% likelihood): Mitigation: bet on inference and workflow integration.
2. Hyperscalers commoditize the stack (60-70% for horizontal infrastructure): Mitigation: vertical specialization in niches hyperscalers won't optimize.
3. Agents don't achieve product-market fit (20-30%): Mitigation: even narrow use cases are multi-billion dollar markets.
4. Regulatory constraints slow deployment (30-40% in healthcare/finance): Mitigation: governance-first approaches become moats.
5. Open source erodes margins (70%+ for undifferentiated inference): Mitigation: move up the stack to applications and workflows.
Investment Framework
Strong signals: Unit economics improving with scale, technical depth beyond wrappers, customer lock-in through data/workflow, domain specialization, measurement discipline.
Red flags: Generic API wrappers, agent demos without production deployments, cost structures that don't scale, undifferentiated infrastructure, no plan for model improvements.
Market sizing: GenAI inference market ~$5-8B (2024) growing to $30-50B (2027). Post-training services: $5-10B. Agent infrastructure: $3-8B.
Investment strategy: Large bets on vertical applications with clear ROI. Medium bets on infrastructure with network effects. Small bets on horizontal infrastructure (high risk but large TAM).
Closing Thoughts
The GenAI landscape is shifting from foundation model training to deployment infrastructure. Companies mastering post-training, inference optimization, and agent orchestration will capture disproportionate value over 3-5 years.
“Cheap intelligence” is a literal engineering requirement for GenAI to move from demos to ubiquitous deployment.
Winning teams need more than AI researchers. They need software engineers who understand workflow integration, guardrails, evaluation pipelines, and production systems. The shift from research to manufacturing is as much about engineering culture as it is about technical capability.
Investors who distinguish between teams building products and those building demos (and assess whether moats are real or will be commoditized) will be well-positioned for the next wave of GenAI value creation.